
Kubernetes 101 - Objects

In this Kubernetes 101 series, we will cover the basis of the Kubernetes objects and concepts. The first part walk through the architecture.
- Part 1: Kubernetes 101 - Architecture
- Part 2: Kubernetes 101 - Objects (this article)
Kubernetes Objects
Namespaces
Namespace provide a mechanism for isolating groups of resources within a cluster. One of the use cases can be the creation of different environments for your application (dev and staging).
Names of resources need to be unique within a namespace, but not across namespaces.
Pods
The Pod is the smallest deployable units that can be found in Kubernetes.
It is a collection of one or more containers that share the same network, storage and lifecycle. Each Pod has its own IP address that will be shared by containers within the Pod. It will allow them to find each other via localhost.
Pods are designed to be ephemeral in nature that means they can be destroy at any time.
Pod’s lifecycle
During its lifetime, a Pod go through severals phases. The possible values for phase are:
Pending: The Pod has been validated by theAPI Serverand an entry was created in theetcdbut is not yet scheduled or one or more containers has not ready to run.Running: Pod have been scheduled and every containers have been created. At least one of the container is still up and running.Succeeded: All containers exited without any errors and will not be restarted.Failed: All containers have terminated and a least one of them exited with error. Either a non-zero status code or killed by the system.Unknown: For some reason the state of the Pod could not be obtained.
Pod definition
A definition for a Pod that will be running the image helloworld:1.0
apiVersion: v1
kind: Pod
metadata:
name: helloworld
spec:
containers:
- name: helloworld
image: helloworld:1.0
ports:
- containerPort: 80
Let’s break down the definition as it as the same structure for every objects:
apiVersion: The version of the Kubernetes API we are using to create this objectkind: The type of object we want to createmetadata: Information that describe and identify the object. Usually contains its name,labels,annotationsand optionally the namespace.
Labelsandannotationare key-value pairs,labelsare use to attach identifying attribute andannotationsfor non-identifying one.spec: The definition of the desired state of the object. The format of thespecsection is different for every object.
For a Pod, we will describe a list ofcontainersdefined by aname, animageandports. ThecontainerPortis the port your application is listening to.
ReplicaSets
The ReplicaSet is the object who is in charge of maintaining in a running state the desired number of Pods. It is used to guarantee the availability of a specified number of identical Pods.
For example, let’s assume we have have 3 Pods running but unexpectedly one of them is killed, the state has 2 Pods instead of 3 (define by the desired state). In order to fulfills its purpose and sticks to the desired state, the replicaSet will spin a new Pod.
It also in charge to scale up or scale down the number of Pods when instructed to.
It’s very rare to use a ReplicaSet directly, but it’s important to understand the concept as they are used under the wood by Deployments.
Deployments
Deployments are the objects used for managing Pods.
The first thing a Deployment does at its creation is to create a ReplicaSet. Then the ReplicaSet creates Pods according to the number of Pods specified.
A Deployment provides an abstraction over ReplicaSets and Pods through a single interface. It can be used to perform rolling update or scaling your application.
Deployment’s lifecycle
During its lifetime, a Deployment enter in various states describe below:
Processing: The Deployment is still working on created resources, performing the rolling update or scaling the number of pods.Completed: The Deployment successfully performed the update, or every replicas (Pods) are in a running state after the scaling, or the creation go through without any error.Failed: Indicate that an error occurred with the Deployment.
Deployment definition
A definition for a Deployment that will be running the image helloworld:1.0
apiVersion: apps/v1
kind: Deployment
metadata:
name: helloworld-deployment
labels:
app: helloworld
spec:
replicas: 3
selector:
matchLabels:
app: helloworld
template:
metadata:
labels:
app: helloworld
spec:
containers:
- name: helloworld
image: helloworld:1.0
ports:
- containerPort: 80
DaemonSets
A DaemonSet ensures that a specific Pod runs on all Nodes. When a node is added or removed, a Pod is either spin or garbage collected.
This is useful for running monitoring or logging solutions for example.
DaemonSet definition
Still using the image helloworld:1.0.
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: helloworld-daemonset
labels:
app: helloworld
spec:
selector:
matchLabels:
name: helloworld
template:
metadata:
labels:
name: helloworld
spec:
containers:
- name: helloworld
image: helloworld:1.0
ConfigMaps
A ConfigMap is an object to store non-sensitive data as key-values pairs. It offer the ability to separate the configuration from the image, then it’s possible to change the configuration without building the image again.
There is 3 ways to consume ConfigMaps
- As command-line arguments
- As environment variables
- By mounting it as configuration files inside the container
It’s possible to create ConfigMaps from literals, files or directories.
Let’s have an example to fully understand ConfigMaps. Create the following ConfigMap
apiVersion: v1
kind: ConfigMap
metadata:
name: my-config
data:
color: blue
bg-color: green
We will consume our configuration through environment variables, to do through configuration files, you need to use Volumes.
apiVersion: v1
kind: Pod
metadata:
name: demo
spec:
containers:
- name: demo
image: k8s.gcr.io/busybox
command: [ "/bin/sh", "-c", "env" ]
envFrom:
- configMapRef:
name: my-config
restartPolicy: Never
By checking the pod’s logs we can see our configuration is successfully used as environment variables.
Secrets
Secrets are very similar to ConfigMaps but are meant to store sensitive data. Be aware that Secrets are only base64 encoded, so its not that secure.
They can be consumed the same ways as ConfigMaps.
Service
A Service is an abstraction to expose your application (a set of Pods).
Services will handle the load-balancing on your application Pods by keeping the list of available endpoints. When a Pod is add or remove, the endpoint list is updated accordingly.
Services also provide an internal DNS record SERVICE_NAME.NAMESPACE_NAME.svc.cluster.local.
The most common types of services are:
ClusterIP: Expose the service as an internal load-balancer. It makes the Service only reachable from within the cluster.NodePort: Expose the service on each Node’s IP at a static port. You can reach the service externally by requestingNODE_IP:NODE_PORT.LoadBalancer: Exposes the Service externally using a cloud provider’s load balancer.
Service definition
A ClusterIP service definition looks like:
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
type: ClusterIP
ports:
- targetPort: 80 # Port on which your container is listening
port: 80 # Port on which your service will listen
Ingress
Basically an Ingress exposes HTTP and HTTPS routes from outside the cluster to services within the cluster. It offers load balancing, SSL termination and provides external routable URLs.
Generally Ingress requires to have an Ingress Controller installed such as Nginx or Traefik.
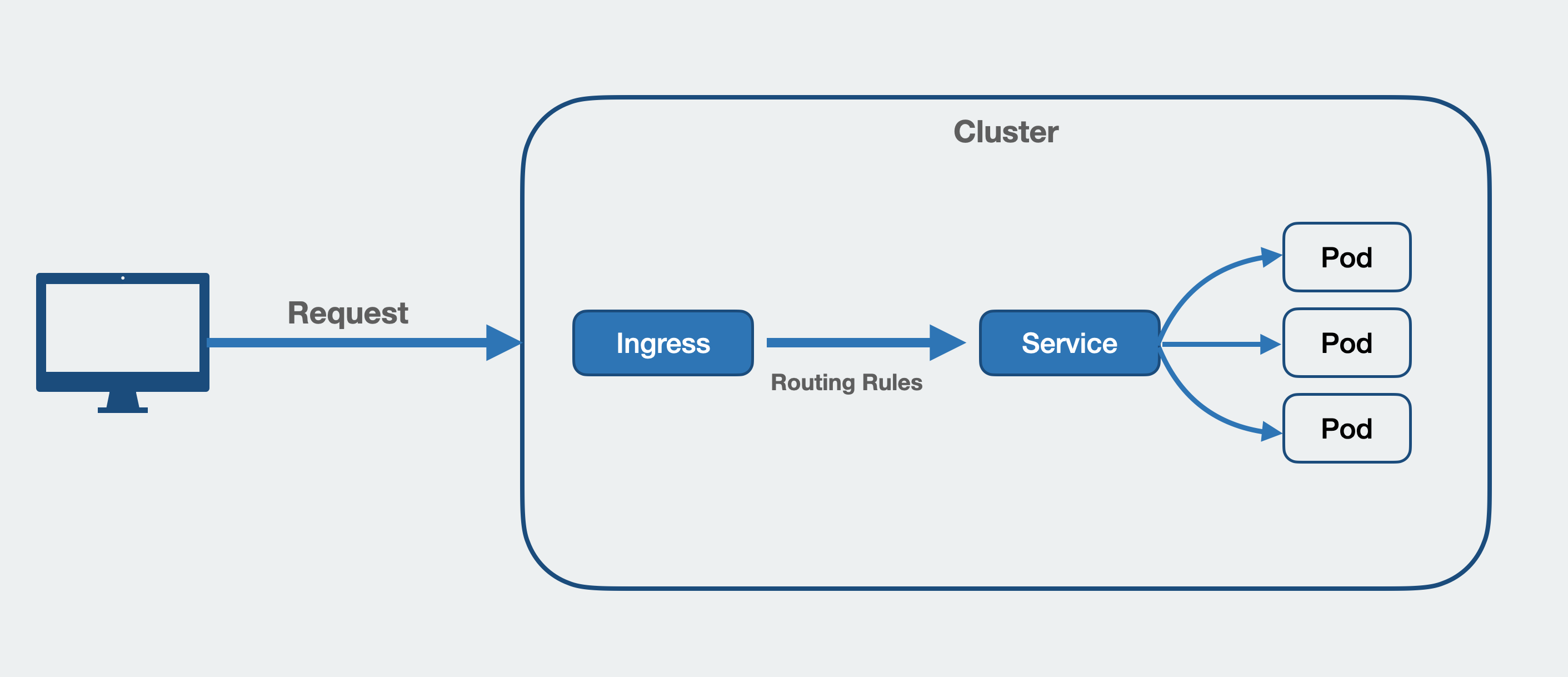
Ingress definition
A simple Ingress definition looks like:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: my-ingress
spec:
rules:
- http:
paths:
- path: /somePath
pathType: Prefix
backend:
service:
name: my-service
port:
number: 80